
Let’s start to design a file hosting service like OneDrive, Dropbox or Google Drive. These kind of file hosting services are given by Cloud providers ( e.g. Google, Amazon, Micorosft, Oracle, AliBaba and so forth) as Saas (Software as a Service).
1. Requirements
Generally, first thing to design a system is to clarify all the functional and non-functional requirements. If you attend a interview, you need to ask what the interviewer has in mind. General design of the system or specific requirements of the system.
A. Functional Requirements
As a top-level functional requirements of our system can be
- Users should be able to upload the files from any place
- Users should be able to download the files from any place
- The system should be able to support folder like filing system.
- Users should be able to share files or folders with other users.
- The system should be able to synchronize the files and folders.
- The system should support storing large files.
- The system should support offline editing
- ACID-ity is required. Atomicity, Consistency, Isolation and Durability of all file operations should be guaranteed.
B. Non-Functional Requirements
Considering non-functional requirements is important in building a scalable system that can efficiently serve millions of users. Here are some of the characteristics that we will want in a scalable file sharing service.
- The system should be highly available, with minimum latency from anywhere and anytime
- The service should guarantee that once a file is uploaded, it will not be lost. (reliability)
- The system should be highly scalable.
C. Assumptions & Considerations
Before starting to design a system, we totally understand the needs, assumptions and considerations,
- Let’s assume that we have 100 million total users (TU),
- Let’s assume that we have 10 million daily active users (DAU).
- Let’s assume that on average each user connects from three different devices.
- Let’s assume that the average number of files per user is 200 files e.g. pdf, docs, images etc.(ANFpU)
- Let’s assume that average file size is 1,5 MB (AFS)
- Let’s assume that we will have 1 million active connections per minute. (ACpM)
- Let’s assume that we stored in small parts or chunks (say 4MB); this can provide a lot of benefits i.e. all failed operations shall only be retried for smaller parts of a file. If a user fails to upload a file, then only the failing chunk will be retried. (CS)
- Let’s assume that we have huge read and write volumes. ( in some cases this can be different because of storage type services)
- Let’s assume that read to write ratio is expected to be nearly the same.
- We can reduce the amount of data exchange by transferring updated chunks only.
- By removing duplicate chunks, we can save storage space and bandwidth usage.
- Keeping a local copy of the metadata (file name, size, etc.) with the client can save us a lot of round trips to the server.
- For small changes, clients can intelligently upload the diffs instead of the whole chunk.
2. Estimations
Assumption is 10 million active users, 200 files per user and average size is 1.5 MB..
A. Capacity/Storage Estimation
To make calculation simpler just take conversation from MB to PB
Average Storage per User (ATSpU) = ANFpU x AFS = 200 x 1.5 MB = 300 MB data per user
Total Storage (TS) = TU x ATSpU =300MB x 100 million = 30 billion MB = 30 million GB = 30 PB (petabyte) data storage
B. Bandwidth Estimation
Consider that daily activity is 10 million active users, 20 files per user daily for read or write and average size is 1.5 MB per file. Let’s assume that upload view ratios is same. e.g. for every files after upload, user will view one time per day.
Average Bandwidth per Second (ABpS)= DAU x FpD x AFS
ABpS = 10 million x 20 files x 1.5 MB = 300 million MB /day = 300.000 GB/ 86400 sec ~= 3.5 GB/sec
Assuming an upload and download ratio is same, we would need ~3.5 GB/sec download and upload bandwidth.
3. High Available Design
At a high level, we need to store files on cloud storage and their metadata information on metadata storage (SQL or NoSQL databases) like;
- file name,
- file size,
- file type
- directory/full path,
- create/update date, etc.,
and who this file is shared with. We need some servers,
- Block servers will work with the clients to upload/download files from cloud storage and Metadata servers will keep metadata of files updated in a SQL or NoSQL databas
- Synchronization servers will handle the workflow of notifying all clients about different changes for synchronization
- Metadata Servers can facilitate updating metadata about files and users
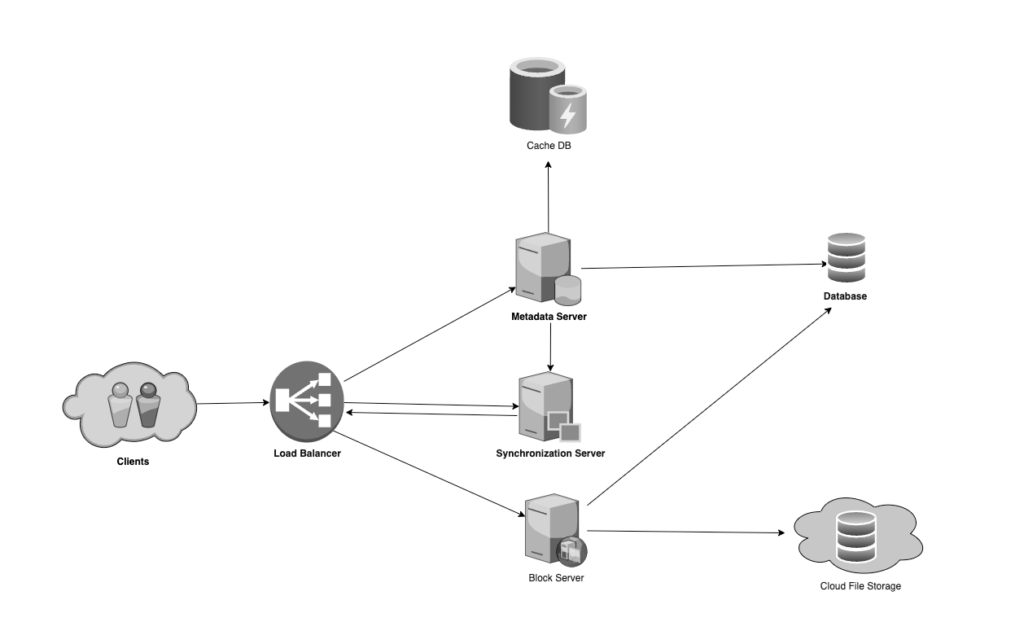
we can additional servers here but for simplicity these are enough for now.
For component design, file processing flow, data deduplication and metadata partionining, cahing and load balancer part , please see the page and support me.